Believe it or not, there is a cure-all for IT support’s woes, and it’s just a simple extension to what support teams currently do.
At least, with some service tool configuration and a little customisation, the following can be achieved:
- Reliable timeliness regardless of ticket age.
- Continuously communicated expectations of when progression will happen.
- Removal and reduction of support’s biggest constraint – ticket ownership silos.
- Bottleneck monitoring for flow management.
- Accurate time-based metrics.
- Exceptionally high service level target achievement.
- SLA breach prevention.
- Service portal purposing for urgent needs.
What needs fixing? Ticket prioritisation
Ticket-level prioritisation works to guide a first response, but if a ticket is not completed at that point, the only additional guidance is the service level target time and its breach warning. There is no guidance on when mid-lifecycle activity should happen.
Additionally, there is no means to identify and prioritise low impact urgent needs – the “quick fix” things that people need to be helped with straight away. So, for this kind of support, recipients must get hold of a service desk team member straight away, by using channels other than the service portal. Problem is, when there is a long wait time, a phone or chat channel is not reliable for urgent needs.
What is the fix? Activity prioritisation
Your service desk might have added some non-standard ticket lifecycle statuses, to provide a degree of ticket differentiation. Activity prioritisation takes this common enhancement a little further.
As long as a full set of lifecycle statuses is available covering what needs to happen next in all “new” and in-progress scenarios, they can be used for activity prioritisation.
In the basics, a level of priority is designated for each status; then support team members simply select an updated status each time a ticket is touched, and status queues are presented on a status priority dashboard for teams to work from. Lifecycle statuses are progressed onwards by working from left to right and top to bottom, with lower priority statuses (towards the right) being approached only periodically.
Don’t own tickets. Own timeliness instead.
Personal ticket queues are perfect silos – highly inefficient and vulnerable. Unfortunately, they are a necessary constraint, unless, that is, a system of status prioritisation is introduced.
For a service desk, support tasks are relatively straightforward, and the team’s skillset and knowledge tend to be similar. So from that perspective, it is generally not necessary to own tickets. In a status priority system (SPS), team-wide functional roles such as “triage” or “first-line” can be given responsibility for a sub-set of statuses that are relevant and appropriate for the role. By working in this way, assignment of tickets to ownership silos can be almost completely avoided.
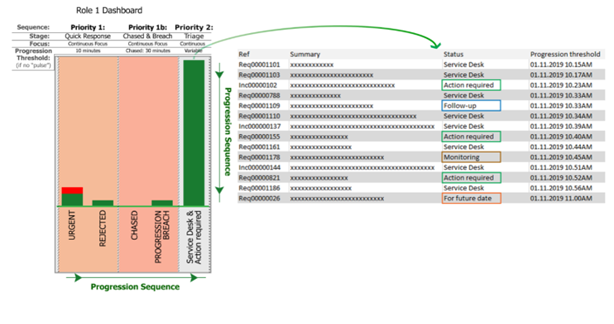
Better still, in “control-by-role”, higher priority statuses are owned by more than one role, and in larger teams more than one person will cover a role, so ticket cover is multiplied, often many times over.
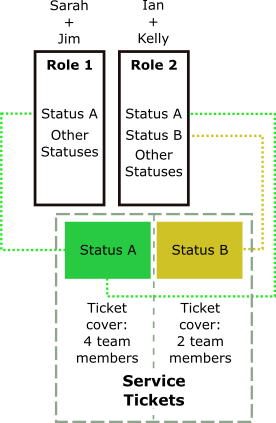
Multiplied ticket cover ensures progression of all open tickets even when individuals are pulled away from support or are on leave. This fulfils the team’s purpose of always being able to meet needs and expectations, compromised only when work demands increase, or team cover is reduced.
But what about work accountability if tickets aren’t owned?
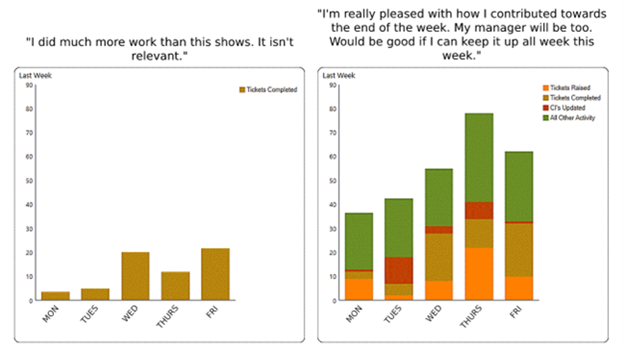
In the siloed way of working, accountability might be pursued by measuring how many tickets are completed. It’s not a good metric, however. When a ticket is closed, it is merely an aside to what teams do on the run-up to completion. Furthermore, a closed ticket does not mean the recipient’s need was met. Activity is what teams do to achieve that essential outcome.
Put differently, activity is where customer satisfaction is experienced, and activity prioritisation makes sure it happens. Knowing how much activity is being carried out, and knowing when flow of activity has stalled, is far more useful and relevant than having a number for how many tickets are completed.
When journals and other “input” activity are measured, activity flow metrics are formed, including true “contribution recognition” that’s unrelated to ticket ownership. Contribution recognition complements role-based ownership of status queues because more activity corresponds with more ticket (status) progression. And, correspondingly, this means a greater contribution towards the service customer experience. Activity performance matters. Closed tickets naturally follow.
The SPS super-power: automated status elevation
In more flexible service tools, each status can be configured with a progression threshold period, specifying how soon progression is expected. When a ticket’s status is changed, a progression threshold timestamp is set.
Progression threshold timestamps provide for much improved prioritisation (sequencing) of ticket progression across status queues. Additionally, with an automation process to monitor timestamps and to set a “progression breach” state when the threshold period has elapsed, prompt progression is drawn in when a breach occurs because the progression breach state has a high level of status priority.
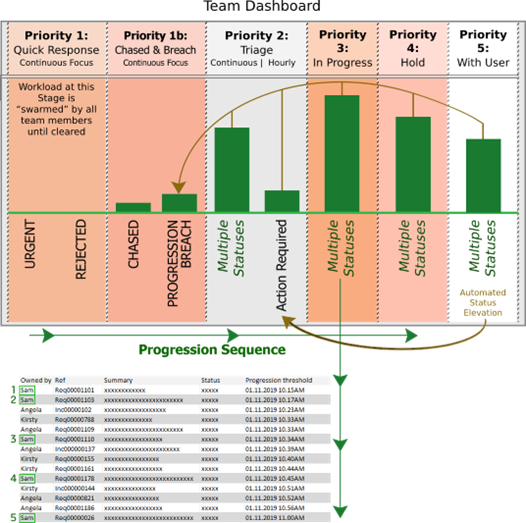
Tickets at a progression breach state are effectively in activity-level backlog. With adequate focus and all else being equal, ticket-level backlog cannot occur.
It’s particularly important to maintain a complete set of statuses when progression thresholds are used, to ensure timeliness across the board.
Expectation management
With the use of progression threshold timestamps, a ticket’s information on a service portal can state something like:
“A team member will progress your ticket within 51 minutes from now. If not, your ticket will be escalated for urgent review. If your need is more urgent, please contact the team”.
With expectations always set and timeliness ensured, backed-up by automated status elevation for exception management, service recipients might never again need to chase a response.
Accurate and high-performing time-based metrics
Each status should be mapped to whether it puts a ticket “on-hold”. When a ticket’s status is changed on every contact, as it is with activity prioritisation, on-hold periods will be accurately excluded from ticket duration, wholly validating a resolution SLA.
With activity prioritisation reducing duration for many tickets and, correspondingly, many more needs successfully being met, SLA achievement will rise, opening scope for a much tighter SLA that reflects the true nature of how well service is delivered. The “watermelon effect” will decline because service experiences will be green inside.
SLA breach prevention
SLA breach prevention works in a similar way to automated status elevation but might include team-wide focus on progression (swarming) ahead of a breach. Additionally, with activity prioritisation, SLA breach warning events should be relatively rare, provided the SLA isn’t tightened too much.
Portal purposing for urgent needs
Classifications of a well-designed service catalogue can be mapped to “urgent” status which, being at the highest level of status priority, can also be team-swarmed for quick response because all roles are responsible for picking up urgent tickets. Service customers are likely to prefer an immediate call back than to wait in a phone or chat queue when they have an urgent need.
Portal purposing for all needs
More broadly, a status priority system purposes a portal appropriately for all manner of service needs because service becomes reliable. Trusted as such, the phone channel could be taken out of mainstream use, removing this source of “queue jumping” that commonly reduces effective prioritisation and is the source of many negative service experiences due to wait time and phone call abandonment.
Even without control-by-role, the process can improve teamwork
At least some ticket ownership will always be necessary for upper support tiers. By using a team-wide status priority dashboard, colleagues see when their co-workers need assistance, particularly when checking the “progression breach” queue.
Rather than rely on team members to help one another, proactive teamwork can be embedded by establishing an upper tier role that is responsible for tickets that fall into progression breach regardless of who owns the ticket, thus preventing a backlog from building.
Conclusion
That’s about it. IT support’s most harmful issues are straightforward to fix.
Further information
Activity Prioritisation is explained further in the microlearning courses “Perfect Prioritisation in 10-minutes“, and “IT Support Service High Performance Principles”.

David Stewart
David Stewart is the author of TOFT - 12 tool-based practices that fill Incident and Request Management gaps.
