I recently had the privilege to attend an award-winning DevOps in-room simulation, hosted by itSMF UK, Sofigate, and G2G3 in London; which was a powerful experiential learning workshop.
Purpose
 By having an immersive face-to-face experience, removing the complexities of day-to-day business whilst focusing on the best practices, tools, and transformation opportunities, people quickly and effectively were able to identify how they can better understand the end-goal of the business (helping sell more), whilst appreciating the need to develop clear strategies to transform the delivery of IT to support the business in achieving this goal.
By having an immersive face-to-face experience, removing the complexities of day-to-day business whilst focusing on the best practices, tools, and transformation opportunities, people quickly and effectively were able to identify how they can better understand the end-goal of the business (helping sell more), whilst appreciating the need to develop clear strategies to transform the delivery of IT to support the business in achieving this goal.
This specific focus of the workshop was based on the roles of getting software developed and into production as efficiently and effectively as possible.
Format
Shortly after arrival, attendees were given a brief presentation, talking us through an overview of the simulation, including RBS CIO’s Case Study.
As part of the presentation, we were then introduced to the simulation software; the heart of the sim:
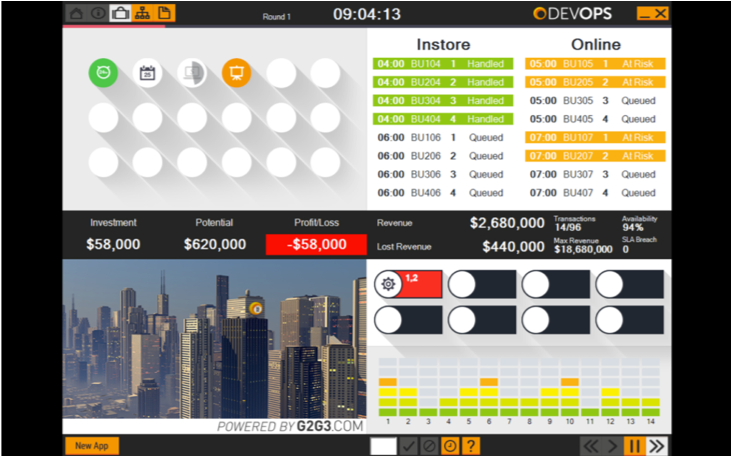
This would guide us in our performance throughout the simulation, showing:
- Realtime sales
- Software releases
- Live incidents
- Profit made/lost
We would use this information to gauge our priorities and decisions during the simulation.
After the brief presentation (and a quick tea break!) we were split into various roles.
The only steer was to encourage people to take on roles which did not correlate to their existing day to day functions; this was to help encourage a greater appreciation for the pressures and constraints of other departments and seemed to work well.
The roles we used in our simulation included:
- The business (where I plumbed to sit 😊)
- Product owner/Scrum master
- Development teams (x2)
- QA
- Service desk
- Release and,
- Operations
Once allocated, each area received a brief overview of their duties; each with very different resources simulating the different tasks to be undertaken by each area.
The business desk was very busy with either new software to build, backlog to clear, or logging incidents to the service desk as they came up on the board.


The simulation was then broken down into three twenty-five minutes “rounds”, using “game dynamics” to recreate IT and business interactions during a normal working day.
Round 1 – Chaos
This initial step had each of us clearly focused on our own silo areas. Work was badly organised, with teams being clearly isolated and disconnected, resulting in slow progress, generating frequent and often significant errors. Ultimately, the business performed poorly in the market.
By the end of round 1, each area had clear ideas of what was causing constraints (blue) and where there were opportunities to improve how we were working (pink).
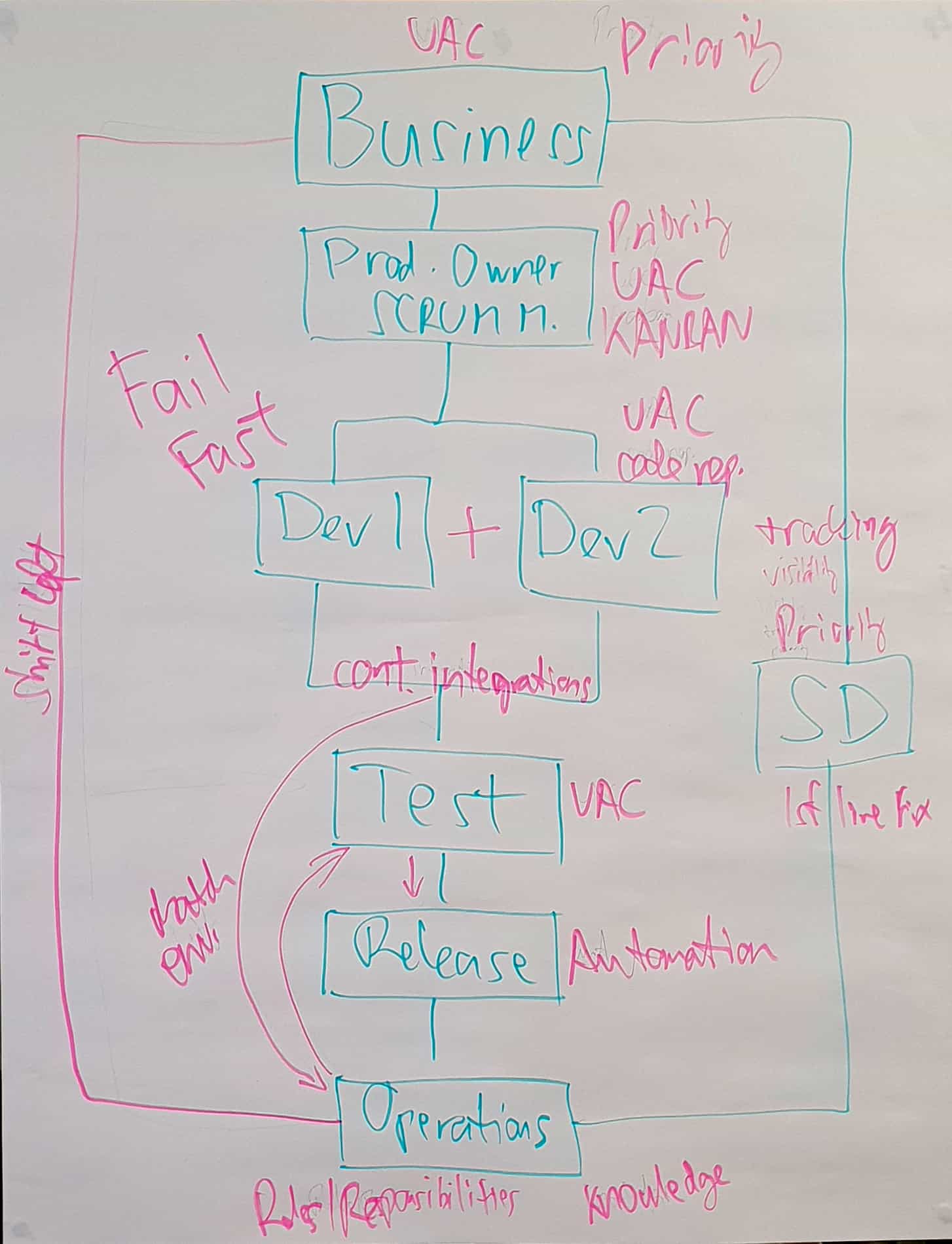
We went around, area by area, identifying what each’s requirements were and where these were lacking.
Business Improvements
For my area, not having site of Developments Progression and Incident Progression was frustrating, particularly when able to clearly see the continual loss of revenue ticking over!
Other Opportunities
Each area subsequently put forward their own ideas:
- Service Desk lacked priority from the business, and had no tracking of tickets.
- Ops Break Fix had no appreciation of service level agreements (SLAs) or business priority of incidents, and had no repository for knowledge to fix repeat issues faster on recurrence.
- Development, Product Owner, and Test had no User Acceptance Criteria to verify if the final product was meeting the business requirements, leaving open to interpretation and guess work.
- Release was chasing around for approvals (release codes) from departments who had already been involved and handed off work, now being interrupted for something effectively already approved.
Round 2 – Improved
Taking onboard what we’d learnt from Round 1, we set to putting things in place to improve things, taking 15 minutes to prepare for Round 2.
Work was getting more organised, including prioritising information from the business, incidents and development work were being tracked using kanban boards, and incident’s were being prioritized by the business and service desk, and knowledge wasbeing recorded in operations. For development, testing, and operations teams, having the business establish a User Acceptance Criteria for each new build being put across, ensured these were more aligned, preventing erroneous work earlier in the cycle, resolving these quicker. As the business was more engaged throughout the process, more value was delivered and greater profit generated!
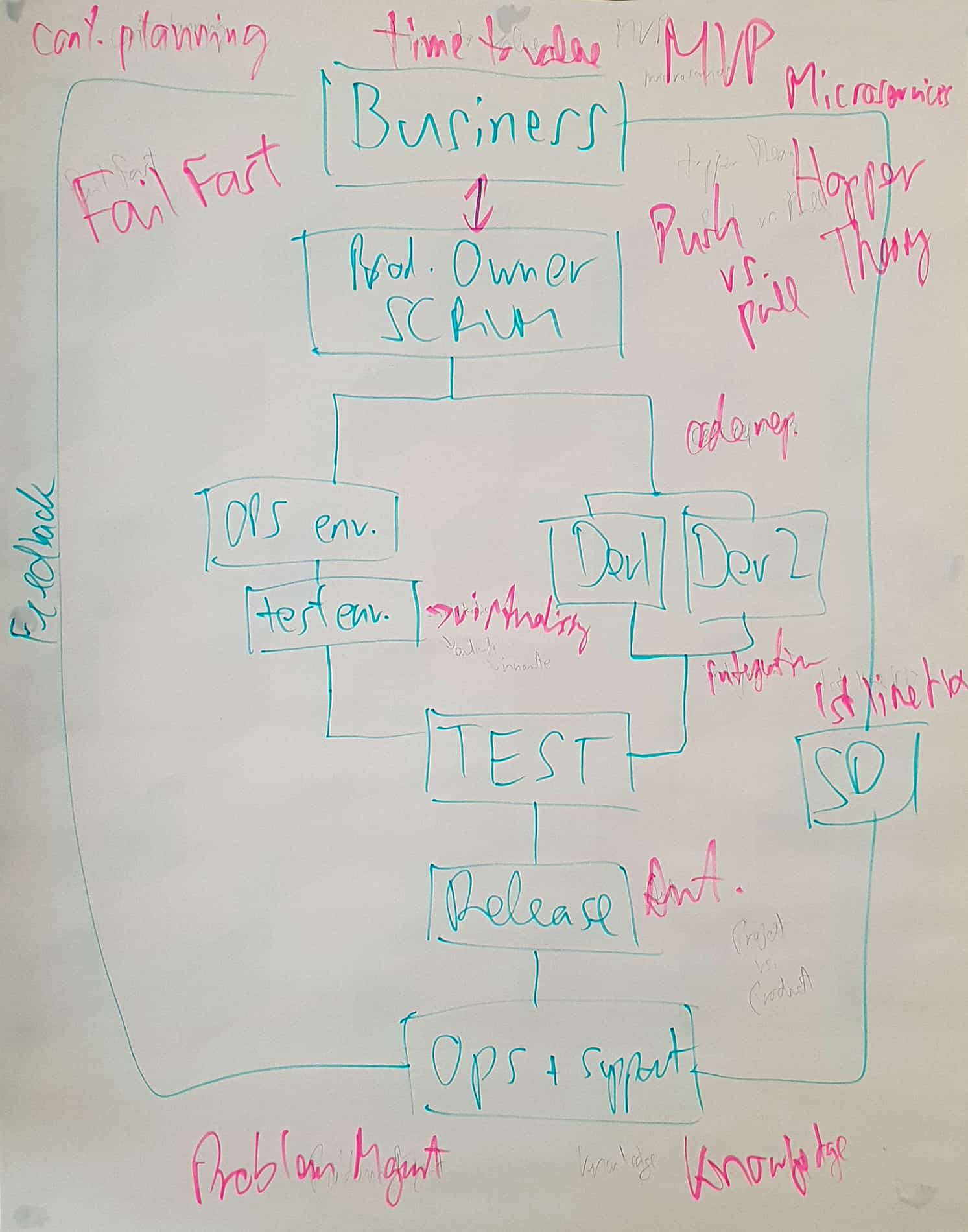
However, there was still further room for improvement! And, after round two, spurred on by the marked difference in what we had been able to achieve (profits had doubled from Round 1!), we set to identifying what else we could improve!
We started identifying opportunities for minimal viable products (MVPs), making releases quicker, increasing profits incrementally.
Service Desk were still purely log and flog with no knowledge; sharing this from operationss helped empower them to carry out first time fixes (FTFs), reducing incident downtime, increasing availability, and therefore also profits!
Also, introducing problem management in operations, through incident trend analysis, helped identify development opportunities to decrease incidents, increasing time to spend on further improvements equaling greater profits!
Furthermore, by ensuring operations live environment was determined prior to testing ensured user acceptance testing (UAT) was conducted in the same environment, further reducing risks, improving solution robustness, and therefore further increase in profits!
Round 3 – Optimised
By embracing opportunities for further automation and potential virtualisation technologies (aligning development and operations environment builds), we delivered a significantly greater throughput of developments and at a far greater quality! (round 2 saw four developments released in 25 minutes, round 3 saw 16 released in the same time frame). Technical debt was also considerably reduced, most incidents being resolved with no impact to profit (the only exception that occurred was where a development resource was required to resolve the incident). Teams were much better aligned, end to end, right across the business.

Simulation Summary
Over three rounds, working across teams, the DevOps simulation demonstrated the business value and positive impact of embracing a DevOps approach and incorporating such systems as scrum and agile into our daily working.
DevOps is a culture and a philosophy, and has many practical applications which can bring a greater level of agility, required for the business to deliver its market advantage. We’re faced with needing to respond more rapidly than ever to changing business demands, and this helps highlight how DevOps can bring about the opportunity to eliminate the consumption of wasted resources, better spent focusing on what really matters.
Why do we need DevOps?
The use of DevOps in IT service management (ITSM) helps an organisation to:
- Eliminate IT silos
- Improve collaboration between teams, both inside IT and with the rest of the business
- Gain greater control over work in progress, enabling IT to detect issues quicker and provide speedier resolutions
- Respond more effectively to accelerated demand for IT products and services
- Shift focus from unplanned, low value activities to productive value-add activities
- Increase efficiency by removing bottlenecks and duplication of effort/rework
- Improve productivity through better ways of working brought about by experimentation and learning
- Increases the organisational capability to change
- In a nutshell, DevOps good practices offer organisations operating traditional ITSM ways of working with new concepts and approaches that allow people to work better together in pursuit of improved business-level outcomes and results.
If this sounds of interest to you then I can highly recommend that you attend a DevOps simulation workshop in the future.
FREE for itSMF UK members to attend, you can find future dates here.

Raymond Paxton
Raymond has over 10 years’ experience working in service management across multiple Financial and Public-Sector Services. Beginning his career in Insurance Services, managing teams transition through multiple big brand identities. In 2007, Raymond joined the largest mental health Trust in the UK on the Service Desk. Being quickly promoted, he managed a portfolio of works, achieving National Accreditation, securing future organisational growth. Raymond then moved back to Private Sector Financial Services in 2015, working for a UK wide organisation, liaising with over 55 CEO’s to identify, capture, monitor, measure, and report achievement of service level requirements.